
生成AIはビジネスのあり方、社員の働き方に大きな影響を与えると言われ、2022年のChatGPTの登場により、更に注目を集めています。今回のコラムでは、ChatGPTをカスタマイズするためのファインチューニングプロセスとその興味深い結果についてご紹介します。
ファインチューニングとは
まず、ファインチューニングとは何かをChat GPT自身に説明してもらいました。
ファインチューニング(Fine-tuning)は、機械学習やディープラーニングの文脈で使われる用語で、ある事前に学習済みのモデルを、特定の新しいタスクやデータに対応できるように微調整するプロセスを指します。
ビジネスへの応用
ビジネス環境では、ファインチューニングによって、企業独自のデータやニーズに合わせたAIモデルを開発できます。今回、私たちは「架空の社内規則」を使用してファインチューニングを試してみました。
手順としては大きく分けて3つです。
ステップ1 : 学習用データの作成
はじめに学習用データとしてAIへの指示文と質問、回答のセットを10個用意し、jsonlファイルを作成しました。
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "採用は何歳からですか"}, {"role": "assistant", "content": "会社は、15 歳以上の者で就職を希望する者の中から、採用試験に合格し、所定の手続を経た者を従業員として採用する。 "}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "試用期間はありますか?"}, {"role": "assistant", "content": "新たに従業員として採用された者は、入社の日から 12ヶ月間を試用期間とする。ただし、その適性を見極めるため、さらに 3 ヶ月以内の範囲で試用期間を延長することがある。また、会社が必要とする特別の技能や経験を有する者には試用期間を短縮、または設けないことがある。 "}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "採用者の提出書類は何ですか?"}, {"role": "assistant", "content": "選考試験に合格して会社に採用された者は、必要に応じて自身の写真を提出しなければならない。"}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "定年は何歳ですか?"}, {"role": "assistant", "content": "従業員の定年は満45歳とし、45歳に達した年度の末日をもって退職とする。ただし、本人が希望し、就業規則に定める解雇事由又は退職事由に該当しない者については、65歳まで勤務延長とする。 "}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "退職する場合はいつまでに会社に報告しないといけないですか?"}, {"role": "assistant", "content": "従業員が自己の都合で退職しようとする場合には、少なくとも 2日前までに退職願を提出しなければならない。ただし、やむを得ない事情がある場合はこの限りではない。"}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "就業時刻は何時ですか?"}, {"role": "assistant", "content": "就業時刻は休憩を除き、1 日について 4時間とし、勤務時間は自由勤務とする。"}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "休日はいつですか?"}, {"role": "assistant", "content": "休日は、毎月1日、11日、21日、31日と祝日とする。"}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "有給休暇はいつから使えますか?"}, {"role": "assistant", "content": "会社は、6ヶ月間勤務し、所定就業日数の 8割以上出勤した従業員に対し、40日の年次有給休暇を毎年与える。 "}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "有給休暇の申請方法はなんですか?"}, {"role": "assistant", "content": "従業員は、年次有給休暇を受けようとする場合には有給休暇消化後に、会社へ申し出なければならない。"}]}
{"messages": [{"role": "system", "content": "You are a helpful assistant. Answer in Japanese!"}, {"role": "user", "content": "正規雇用になれますか?"}, {"role": "assistant", "content": "勤続 36ヶ月以上の者で、本人が希望する場合は、正規雇用に転換させることがある"}]}ステップ2 : 作成データをOpenAI社のサイトにアップロード
OpenAI社のサイトに作成したファイルをアップロードすると準備完了です。今回はPythonでプログラムを作成し、ファインチューニングを実行しました。使用したベースモデルはdavinciです。
ステップ3 : ファインチューニングの実施
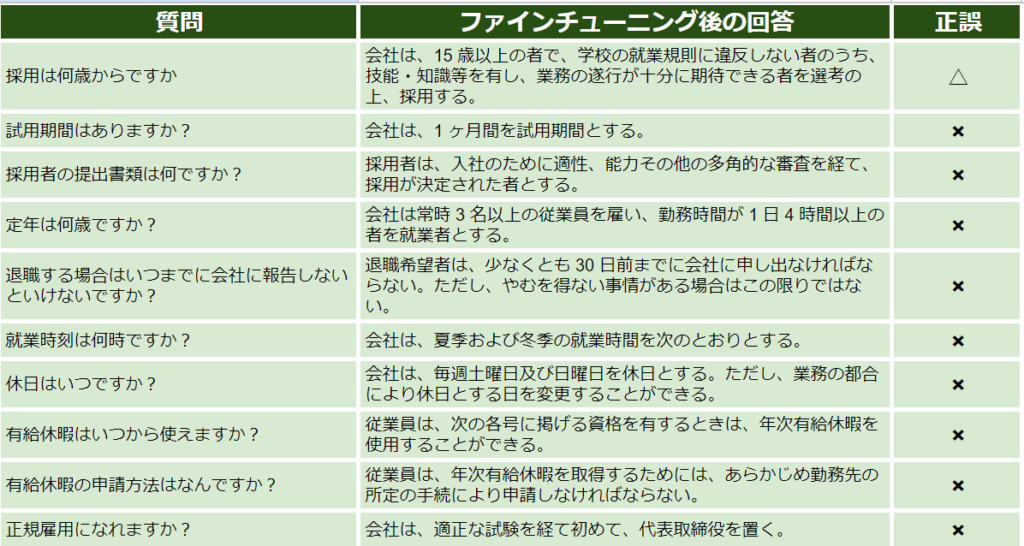
確認のため、一旦学習データの質問をそのまま聞いてみました。
結果
残念ながら、期待した回答はほとんど得られませんでした。
この原因として、学習用データの量が不足している可能性や、既存の学習データに埋もれてしまった可能性を考えています。
今後の展望
大規模な学習データを扱う際、データを「質問」と「回答」の形式に変換し、ファインチューニングを行うプロセスが非常に時間と労力を要すると感じました。さらに、ファインチューニング後のモデルについても正答率の低さから、学習プロセスの難しさを実感しています。
また、今回のファインチューニングの検討費用としては、数百円程度でした。
次回は同様の作業を、OpenAIが提供する「Assistants API」を用いることで、上記の問題点が大幅に改善された記事をご紹介したいと思います。